
Раскрытие секретов SEO: роль машинного обучения в поиске Google
- Восстание машин
- Приложение Google для машинного обучения
- Google также учится благодаря помощи веб-мастеров и оптимизаторов
- Структурированные данные как проверенные человеком данные обучения для алгоритма Google
- Как структурированные данные устарели для покупок в Google
- Вывод: шаги машинного обучения к семантическому пониманию
Что это на самом деле означает, когда мы говорим, что Google использует алгоритмы машинного обучения? В нашей последней статье «Развертывание секретов SEO» приглашенный автор Олаф Копп объясняет, к чему именно это относится и где нейронные сети применяются в Поиске Google. Веб-мастерам и оптимизаторам следует принять во внимание: вы - ключ к тому, чтобы помочь обеспечить алгоритмы Google обучающими данными.

Эта статья является последней в моей серии по машинному обучению. Предыдущие посты распаковки можно найти здесь:
Часть 1: Как Google интерпретирует поисковые запросы
Часть 2: Все это семантически для поиска Google
Часть 3: Как работает график знаний Google?

Развертывание секретов SEO
Как обсуждалось в статье, Семантическая паутина (немецкий) Системы, основанные на инновациях Web 2.0, которые делают информацию идентифицируемой, классифицируемой, измеримой и сортируемой в зависимости от контекста, являются единственным способом справиться с потоком информации и данных.
Но чистой семантики здесь недостаточно, потому что это зависит от статистических методов. Семантические системы требуют предопределения классов и меток для классификации данных. Более того, трудно идентифицировать и создавать новые объекты без помощи вручную. В течение длительного времени это можно было сделать только вручную или со ссылкой на поддерживаемые вручную базы данных, такие как Wikipedia или Wikidata, что препятствует масштабируемости.
Из-за этого, цифровые привратники нуждаются во все более надежных автономных алгоритмах для управления этими задачами. В будущем алгоритмы самообучения, основанные на методах искусственного интеллекта и машинного обучения, будут играть все более важную роль. Это единственный способ гарантировать, что результаты / результаты соответствуют ожиданиям при сохранении масштабируемости.
Восстание машин
Прежде чем перейти к роли машинного обучения в поиске Google сегодня, важно понять, как работает машинное обучение. В своем объяснении я только коснусь этой темы, потому что я не обученный математик или ученый, и мне не хватает более детальных знаний о том, как создаются такие алгоритмы.
Машинное обучение можно считать частью области искусственного интеллекта . Термин «интеллект» не совсем применим в отношении машинного обучения, потому что речь идет не столько об интеллекте, сколько о шаблонах, которые могут распознавать машины или компьютеры, и о точности.
Машинное обучение имеет дело с автоматизированной разработкой алгоритмов, основанных на эмпирических данных или данных обучения. В результате основное внимание уделяется оптимизации результатов или улучшению прогнозов на основе процессов обучения.
Приложение Google для машинного обучения
Эти алгоритмы также часто используются в Google для классификации и кластеризации информации, а также для прогнозирования на этой основе. Согласно собственному заявлению, Google полагается на контролируемое машинное обучение , что означает, что в разные моменты процесса машинного обучения люди предварительно классифицируют и оценивают результаты.
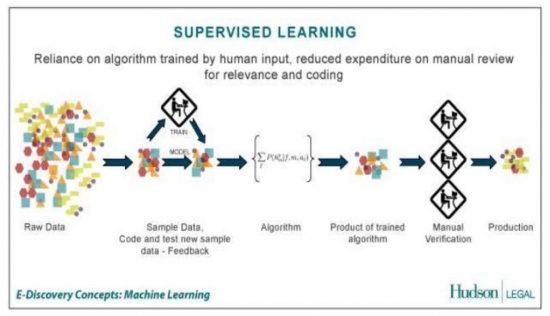
Согласно их собственным заявлениям, Google использует глубокие нейронные сети, по крайней мере, с пятью слоями, которые затем называются Deep Learning . Использование нейронных сетей такой глубины позволяет автоматически и независимо создавать новые модельные группы, что снова значительно повышает масштабируемость
Машинное обучение можно использовать везде, где Google должен назначать метки или комментарии к данным и / или запускать кластеризацию, что было бы слишком трудоемким вручную. До настоящего времени использование машинного обучения в поиске Google было подтверждено только RankBrain. Однако я также могу представить себе, что машинное обучение уже используется для кластеризации документов в процессе индексации. Если вы хотите узнать больше о Google, AI и машинном обучении, я рекомендую мою статью, Значение машинного обучения, AI и RankBrain для SEO и Google (немецкий) с интересными мнениями уважаемых коллег, таких как Маркус Хёвенер, Кай Спристерсбах, Маркус Тобер и Себастьян Эрлхофер.
Google также учится благодаря помощи веб-мастеров и оптимизаторов
Разработка семантической базы данных в форме графа знаний, но также и в целом с идентификацией сущностей, во многом зависит от помощи внешних лиц, таких как веб-мастера и редакторы Википедии. В целом, однако, долгосрочная цель Google состоит в том, чтобы иметь возможность независимо извлекать данные, которые можно интерпретировать, чтобы проект График знаний не останавливался.
Это также очевидно в проекте хранилища знаний. Хранилище знаний было представлено Google в 2014 году как неактивный проект разработки, в котором предполагалось использовать веб-сканирование, машинное обучение, структурированные и неструктурированные данные для создания крупнейшей базы знаний в мире. Кроме того, на сегодняшний день нет информации о том, насколько активно Google уже использует эту базу данных. Но я предполагаю, что граф знаний уже получает информацию из хранилища знаний. Подробнее об этом можно прочитать в статье, Google «Хранилище знаний» для обеспечения будущего поиска ,
Я предполагаю, что Google очень заинтересован в распознавании информации для Графа знаний без помощи внешних людей - и в идеале автоматизирован. Здесь уже есть некоторые подсказки, что Google постоянно предоставляет проверенные человеком данные обучения для своих собственных систем машинного обучения, чтобы быстрее идентифицировать и классифицировать объекты.
Например, Google также дважды проверяет информацию о медицинских коробках профессоров и врачей в Гарварде и Клинике Майо, прежде чем они будут опубликованы в графах знаний. Эта ручная проверка может также использоваться с контролируемым машинным обучением для улучшения алгоритмов. Google может также предоставить алгоритмы самообучения обратной связи с оценщиками поиска (Quality Rater), так как они могут стать еще одним источником ценных учебных данных.
Структурированные данные как проверенные человеком данные обучения для алгоритма Google
Другим примером того, как Google все чаще пытается работать независимо от веб-мастеров, является разметка rel-authorship . На мой взгляд, эта разметка имела только одну цель для Google: идентификация шаблонов, которые используются для определенных типов объектов. Информация и разметки создавались или заполнялись людьми (в основном, SEO-специалистами и веб-мастерами) и, следовательно, были проверенными данными обучения, которые Google мог использовать в своих алгоритмах машинного обучения для создания групп моделей для авторов в соответствии с этими шаблонами.
Таким образом, неудивительно, что Google в конце концов прекратил преследовать проекты rel-авторство или Freebase . Freebase изначально была заполнена данными, которые люди добавляли в соответствии с базовой семантической структурой. Это дало Google и семантическую игровую площадку, и достаточно проверенных человеком данных для обучения алгоритму машинного обучения. Но Freebase был лишь кратковременным средством для достижения цели.
Как структурированные данные устарели для покупок в Google
По моему мнению, это также произойдет в ближайшие несколько лет с большой долей всех структурированных данных, как только Google больше не будет нуждаться в этом. Это также просто проверенные человеком данные обучения, которые в какой-то момент могут устареть.
Тот факт, что структурированные данные могут быть лишь путевой точкой и что Google в идеале хотел бы обойтись без этого ввода в виде тегов веб-мастерами и оптимизаторами SEO, также демонстрируется последними разработками в Google AdWords или Google Shopping.
Рекламодатели AdWords, которые запустили фид покупок в последние несколько месяцев, получили письмо со следующим текстом:
«По состоянию на 30 октября 2017 г. самая актуальная информация о ценах и наличии ваших статей будет определяться на основе аннотаций для структурированных данных или дополнительной информации (если структурированные данные недоступны). Таким образом, ваши клиенты выиграют от повышения удобства использования Google Shopping ».
Если вы иногда обращаетесь к справке Google Shopping, вы найдете следующую формулировку относительно каналов покупок:
«Продвинутые экстракторы могут найти информацию о цене и наличии на целевой странице продукта. Они используют комбинацию статистических моделей и машинного обучения для обнаружения и извлечения данных о продукте из независимой разметки структурированных данных вашего сайта ». Источник: https://support.google.com/merchants/answer/3246284?hl=en
Это показывает, как за последние несколько лет Google с помощью машинного обучения научился автоматически интерпретировать контент, независимый от структурированных данных, и назначать контент классу. Благодаря этому процессу поставщики магазинов оказали важную помощь, которые последние годы послушно пометили свои каналы покупок структурированными данными. Проверенные данные тренировок для алгоритма машинного обучения Google Shopping.
Эта цель четко сформулирована Google, прямо из Гари Иллиеса:
«Я хочу жить в мире, где схема не так важна, но в настоящее время она нам нужна. Если команда Google рекомендует это, вам, вероятно, следует использовать ее, поскольку схема помогает нам понять содержимое страницы, и она используется в определенных функциях поиска (но не в алгоритмах ранжирования)… У Google должны быть алгоритмы, которые могут вычислять вещи без необходимости схемы ... »Источник: https://searchengineland.com/gary-illyes-ask-anything-smx-east-285706
Кроме того, я должен упомянуть, что в той же цитате Гэри отрицает, используются ли данные schema.org в качестве обучающих данных. Это противоречит моему предположению.
«Нет, это используется для богатых фрагментов».
Вывод: шаги машинного обучения к семантическому пониманию
- Google хотел внедрить семантический поиск с Графиком Знаний и алгоритмом Колибри. Однако сегодня ясно, что цель семантического понимания давно не может быть достигнута из-за недостатка масштабируемости.
- Учитывая огромный объем поисковых запросов и документов, семантическая классификация информации, документов и поисковых запросов является практичной только в сочетании с системами машинного обучения. Иначе жертвы в производительности слишком велики. Кроме того, это стало возможным благодаря энергичной помощи SEO-специалистов и веб-мастеров, которые сами помечают информацию вручную.
- Возможность делать прогнозы относительно того, что бы хотел пользователь, когда он вводит ранее неизвестный поисковый термин в строку поиска, возможна только через машинное обучение.
Похожие
SEO... google"> Google а также Microsoft Bing , Также обсуждает представление поисковой системы , история поиска , а также вертикальный поиск , Typo3 SEO
... для трейдеров, все цены, указанные здесь, являются ценами нетто плюс установленный налог на добавленную стоимость в размере 19%. Цены и предложения действительны только для клиентов, проживающих в Германии. Хороший SEO Typo3 необходим для любого веб-сайта с популярной системой управления контентом Typo3 и напрямую связан с успехом сайта. Есть много плагинов Typo3, посвященных поисковой оптимизации. Конечно, так как недостаточно просто загрузить плагин, но его также необходимо настроить Определение SEO
За прошедшие годы моя карьера прошла путь от журналистики до SEO, связей с общественностью и конференций. Часть «SEO» была самой противоречивой. Если бы вы попросили меня дать определение «SEO» несколько лет назад, я бы ответил: «Получив Мемфис SEO
Готовы работать с экспертом в Мемфисе SEO? Сделайте свой бизнес веб-сайт выделиться в крупных городах США Получите отзывчивый сайт с высоким трафиком, вознагражденный Google Найдите в Интернете то, что вы делаете, увеличьте свою экспозицию Развивайте свой бренд и Сакраменто SEO
Joomla 1.5 SEO
... Google Analytics (особое внимание уделяется этому инструменту). Глава 10 - Как получить входящие ссылки. Анализ различных стратегий проводится для получения ссылок для Интернета, таких как оплата через ссылки или участие в форумах и блогах. Также в качестве дополнительного контента включены два приложения. Первый - это исследование SEO, посвященное созданию сети Joomla, которая охватывает все, от выбора доменного имени до подготовки контента, SEO Гарантия
... для оптимизации и повышения эффективности SEO вашего сайта, применяя этические методы SEO. Наш гарантированный SEO сервис демонстрируется нашим опытом и уверенностью в нашей способности ранжировать сайты в основных поисковых системах Google, Yahoo, Bing. Хотя маловероятно, что мы не сможем поставить рейтинг в поисковых системах. Ни одна компания по поисковой оптимизации не имеет никакого контроля над поисковыми системами и не может гарантировать точную позицию в поисковых системах. 10 способов Google+ улучшит ваше SEO
Есть еще люди, которые спорят за ожидание и видят стратегию, прежде чем использовать Google Plus. Они часто указывают на меньшее количество людей, использующих Google Plus. Эти люди в корне неправильно понимают природу Google Plus и то, как он может улучшить ваши результаты SEO, даже если никто из ваших клиентов [Инфографика] Как подписи улучшают SEO
22 мая 2017 года СОФИЯ ЭНАМОРАДО Обновлено: 24 января 2019 г. В последние годы количество устройств с экранами возросло, что соответствует массовому потреблению видео. К 2019 году видео будет составлять 80% всего потребительского интернет-трафика. Видео есть везде, и оно будет только распространяться на наших экранах. Seo Agency Как открыть один
Иметь и открыть SEO агентство сегодня это работа не для всех. У тебя должна быть печень! Например, есть те клиенты, которые пытаются всеми силами помочь вам консультация без того желая вывести даже копейки. Тогда есть те клиенты, для тех, у кого есть агентство поисковая оптимизация Как начать карьеру в SEO
... Google вокруг и выяснить это самостоятельно. Вам не нужно быть профессионалом, чтобы начать. Просто ознакомьтесь с основами, такими как изучение мета-тегов. Пока вы находчивы, вы сможете учиться на ходу. 2. Читать все, что вы можете найти SEO постоянно меняется. Сейчас это радикально отличается от того, что было даже пять лет назад. Вот почему важно всегда быть в курсе последних новостей и всегда читать. Лучшие профессионалы в области SEO - это
Комментарии
Но понимаете ли вы, как внедрить SEO и сделать свой магазин Etsy выдающимся в поиске, как во внутренней поисковой системе Etsy, так и в Google, Yahoo и Bing?Но понимаете ли вы, как внедрить SEO и сделать свой магазин Etsy выдающимся в поиске, как во внутренней поисковой системе Etsy, так и в Google, Yahoo и Bing? Мир SEO может быть обширным и сложным, и он постоянно меняется. К счастью для вас, поисковые системы все больше заботятся об актуальности и удобстве пользователей. Речь идет не о том, чтобы победить систему или что-то вроде хитрости, известной лишь немногим избранным. В наши дни SEO помогает вашим потенциальным Как использовать Google Analytics, чтобы измерить роль SEO в достижении целей сайта?
Как использовать Google Analytics, чтобы измерить роль SEO в достижении целей сайта? Одним из приемов и лучших приемов оптимизации является разработка контента каждой страницы сайта с ключевыми словами, связанными с одной темой. Исходя из этого, каждая страница идентифицируется по определенному сегменту ключевых слов (длинные термины из одной темы). Название и URL страницы отражают основную тему страницы . Эта информация находит свою полезность Что такое структурированные данные?
Что такое структурированные данные? Проще говоря, структурированные данные - это код, который вы можете добавить на свои веб-страницы, который виден сканерам поисковых систем и помогает им понять контекст вашего контента. Это способ описать ваши данные для поисковых систем на языке, который они могут понять. Как структурированные данные связаны с техническим SEO? Хотя структурированные данные имеют отношение к содержанию веб-сайта, они являются частью Он также предоставляет предварительный просмотр о SEO вашего поста / страницы, делая вид, насколько силен ваш сайт SEO?
Он также предоставляет предварительный просмотр о SEO вашего поста / страницы, делая вид, насколько силен ваш сайт SEO? Он генерирует карту сайта XML для вашего сайта. Чтобы сканерам было проще увидеть полную структуру вашего сайта. Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации?
Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации? Создание эффективной стратегии - вот где большинство вопросов вступают в игру, поэтому воспользуйтесь этими пятью советами, чтобы помочь составить план SEO, дающий результаты. О, если вы также подумаете о том, как писать лучше благодаря хорошо выполненной работе по копирайтингу?
Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации? Создание эффективной стратегии - вот где большинство вопросов вступают в игру, поэтому воспользуйтесь этими пятью советами, чтобы помочь составить план SEO, дающий результаты. Как получить видимость благодаря местному SEO?
Как получить видимость благодаря местному SEO? Определение Google My Business (GMB) Это текущий список 3 приложений, предлагаемых Google для местного SEO: Целевая страница GMB GMP PL - это страница, на которую направлено использование одного из GMB. Вы выполняете поиск в Картах Google, Google отображает вашу компанию с помощью интерактивной ссылки. Эта ссылка отправляет пользователя на Но как вам удается быть узнаваемым Google как бренд?
Но как вам удается быть узнаваемым Google как бренд? Важно, что существует определенный объем поиска для бренда. Это означает, что вы уже сделали себе имя в целевой группе. Это как раз то, где начинается формирование бренда. Заинтересованные стороны должны часто вступать в контакт с брендом. Позже, когда они ищут тот или иной продукт, бренд должен прийти им в голову без особых усилий. Кроме того, следует проводить интенсивный контент-маркетинг, чтобы распространять контент с информацией Но как вы можете улучшить свою SEO игру, не делая это очевидным для своих читателей - или не получив наказание от Google?
Но как вы можете улучшить свою SEO игру, не делая это очевидным для своих читателей - или не получив наказание от Google? Читай дальше что бы узнать. 1. Начните с идеального тега заголовка Надежная SEO-стратегия на странице начинается с выбора наиболее эффективных тегов заголовка для вашего контента. Это означает, что для каждой конкретной внутренней страницы вашего сайта - будь то статический контент или уникальный пост в блоге - вам необходимо Хитрость заключается в том, чтобы понять как работают поисковые системы Как работают поисковые системы?
Как хорошо написать, чтобы повысить ваш бизнес, как родить прибыльную контент-стратегию? Ферреоль и его гости исследуют предмет сверху вниз и дают вам ключи, чтобы добраться туда! Сила редакции: книга Ферреоле Леспинасса! GD Star Rating загрузка ... Вы также хотите острый как SEO контент?
Вы также хотите острый как SEO контент? Вы также хотите запоминающийся и гипер-релевантный SEO-текст, который вдохновляет, мотивирует и активирует ваших клиентов? Стратегически продуманный и увлекательный текст, с помощью которого вы можете связаться со своей целевой группой, помочь своим клиентам в дальнейшем и создать базу поклонников вашей компании? Тогда свяжитесь с нами! Потому что весь этот SEO копирайтинг, конечно, должен приносить что-то!
Com/merchants/answer/3246284?
Но понимаете ли вы, как внедрить SEO и сделать свой магазин Etsy выдающимся в поиске, как во внутренней поисковой системе Etsy, так и в Google, Yahoo и Bing?
Как использовать Google Analytics, чтобы измерить роль SEO в достижении целей сайта?
Что такое структурированные данные?
Как структурированные данные связаны с техническим SEO?
Он также предоставляет предварительный просмотр о SEO вашего поста / страницы, делая вид, насколько силен ваш сайт SEO?
Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации?
Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации?
О, если вы также подумаете о том, как писать лучше благодаря хорошо выполненной работе по копирайтингу?
Вы, наверное, знаете, что такое SEO и как оно может помочь вашему бизнесу стать более успешным, но знаете ли вы, как создать эффективную кампанию по поисковой оптимизации?